
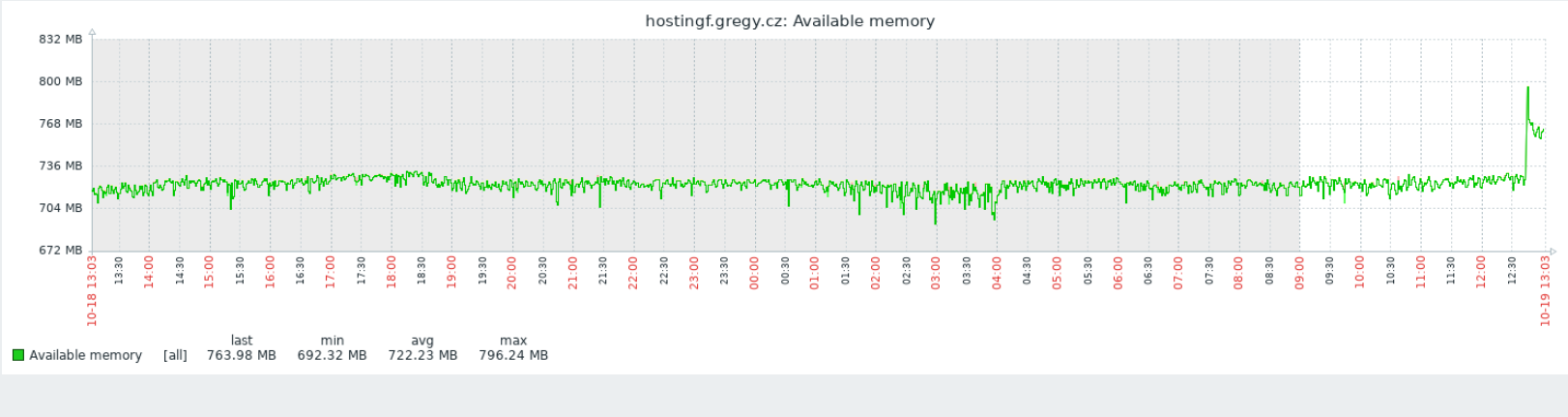
Zdar, rád bych poprosil o pomoc s debugováním OOM killů v mém VM. Měl jsem za to, že mám spoustu volného místa a proto mě kill překvapil (díky za nové reportování z vpsadminu!). VM monitoruji zabbixem a ten tvrdí, že dostupné paměti je dost (špička na konci je kill) [image: image.png]
výstup z free -m vypadá takto:
root@hostingf:~# free -m total used free shared buff/cache available Mem: 1000 238 100 621 661 761 Swap: 0 0 0
/proc/meminfo MemoryAvailable sedí se zabbixem a free: "MemAvailable: 777548 kB"
Trošku zarážející je, že "volné" paměti je pouze 100M. Rozhodující pro OOM je ale "dostupná" paměť, že?
V příloze posílám výstup z dmesg náležící k OOM killu.
Není mi jasné, proč OOM kill vůbec nastal. Součet všech rss v dmesg reportu ani zdaleka nedosahuje 1G. Předpokládám, že mi nějak uniká něco podstatného, ale nevím moc co hledat. Budu rád za každé nakopnutí.
Gregy
{kind=link}

Ahoj,
podle toho reportu jsi mel cca 600 MB v tmpfs, to je taky v RAM a bohuzel se pocita jako 'shmem', takze to vubec neni zrejme, ze je to vlastne tim...
"Problem" prameni z toho, ze pokud neexistuje /var/log/journal, uklada systemd logy do tmpfs pod /run/log/journal - a na to se da docela rychle narazit.
Resenim je vyrobit adresar /var/log/journal a otocit tu VPSku, bude po problemu.
Proc jsme si toho do ted nevsimli s OpenVZ, zjistuju, ale vypada to, ze uz mame hlavniho vinika, proc nam "nevysvetlitelne" ubyva RAMka s pribyvajicim uptime na tech OpenVZ strojich...
V novych sablonach uz to Aither opravil:
https://github.com/vpsfreecz/vpsadminos-image-build-scripts/commit/2872ff1b5...
Ve stavajicich VPS to doresime skriptem behem nasledujicich par desitek hodin.
Ale ty VPSky, kterych se to tyka, zacnou logovat na spravne misto az od restartu (chystame v nasledujicich dnech update vsech vpsadminos nodes na Linux 5.9, takze explicitni restart, pokud s tim zrovna nebojujete, asi potreba neni).
/snajpa
On 2020-10-19 15:18, Petr Gregor wrote:
Zdar, rád bych poprosil o pomoc s debugováním OOM killů v mém VM. Měl jsem za to, že mám spoustu volného místa a proto mě kill překvapil (díky za nové reportování z vpsadminu!). VM monitoruji zabbixem a ten tvrdí, že dostupné paměti je dost (špička na konci je kill)
výstup z free -m vypadá takto:
root@hostingf:~# free -m total used free shared buff/cache available Mem: 1000 238 100 621 661 761 Swap: 0 0 0
/proc/meminfo MemoryAvailable sedí se zabbixem a free: "MemAvailable: 777548 kB"
Trošku zarážející je, že "volné" paměti je pouze 100M. Rozhodující pro OOM je ale "dostupná" paměť, že?
V příloze posílám výstup z dmesg náležící k OOM killu.
Není mi jasné, proč OOM kill vůbec nastal. Součet všech rss v dmesg reportu ani zdaleka nedosahuje 1G. Předpokládám, že mi nějak uniká něco podstatného, ale nevím moc co hledat. Budu rád za každé nakopnutí.
Gregy
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list
Díky moc za rychlou a přesnou odpověď. Můj odhad proč se to děje je, že journald limituje velikost logů podle procenta místa na cílovém zařízení. Tmpfs bohužel reportuje v Available ram celého nodu (podobný problém jako https://github.com/vpsfreecz/vpsadminos/issues/45).
Z dokumentace journald:
SystemMaxUse= and RuntimeMaxUse= control how much disk space the journal
may use up at most. SystemKeepFree= and RuntimeKeepFree= control how much disk space systemd-journald shall leave free for other uses. systemd-journald will respect both limits and use the smaller of the two values.
The first pair defaults to 10% and the second to 15% of the size of the
respective file system
On Mon, Oct 19, 2020 at 3:39 PM Pavel Snajdr snajpa@snajpa.net wrote:
Ahoj,
podle toho reportu jsi mel cca 600 MB v tmpfs, to je taky v RAM a bohuzel se pocita jako 'shmem', takze to vubec neni zrejme, ze je to vlastne tim...
"Problem" prameni z toho, ze pokud neexistuje /var/log/journal, uklada systemd logy do tmpfs pod /run/log/journal - a na to se da docela rychle narazit.
Resenim je vyrobit adresar /var/log/journal a otocit tu VPSku, bude po problemu.
Proc jsme si toho do ted nevsimli s OpenVZ, zjistuju, ale vypada to, ze uz mame hlavniho vinika, proc nam "nevysvetlitelne" ubyva RAMka s pribyvajicim uptime na tech OpenVZ strojich...
V novych sablonach uz to Aither opravil:
https://github.com/vpsfreecz/vpsadminos-image-build-scripts/commit/2872ff1b5...
Ve stavajicich VPS to doresime skriptem behem nasledujicich par desitek hodin.
Ale ty VPSky, kterych se to tyka, zacnou logovat na spravne misto az od restartu (chystame v nasledujicich dnech update vsech vpsadminos nodes na Linux 5.9, takze explicitni restart, pokud s tim zrovna nebojujete, asi potreba neni).
/snajpa
On 2020-10-19 15:18, Petr Gregor wrote:
Zdar, rád bych poprosil o pomoc s debugováním OOM killů v mém VM. Měl jsem za to, že mám spoustu volného místa a proto mě kill překvapil (díky za nové reportování z vpsadminu!). VM monitoruji zabbixem a ten tvrdí, že dostupné paměti je dost (špička na konci je kill)
výstup z free -m vypadá takto:
root@hostingf:~# free -m total used free shared buff/cache available Mem: 1000 238 100 621 661 761 Swap: 0 0 0
/proc/meminfo MemoryAvailable sedí se zabbixem a free: "MemAvailable: 777548 kB"
Trošku zarážející je, že "volné" paměti je pouze 100M. Rozhodující pro OOM je ale "dostupná" paměť, že?
V příloze posílám výstup z dmesg náležící k OOM killu.
Není mi jasné, proč OOM kill vůbec nastal. Součet všech rss v dmesg reportu ani zdaleka nedosahuje 1G. Předpokládám, že mi nějak uniká něco podstatného, ale nevím moc co hledat. Budu rád za každé nakopnutí.
Gregy
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list

IMHO neni třeba otáčet vps, stačí systemctl daemon-reload
*Matěj Koudelka* +420 604 266 933
On Mon, 19 Oct 2020 at 15:39, Pavel Snajdr snajpa@snajpa.net wrote:
Ahoj,
podle toho reportu jsi mel cca 600 MB v tmpfs, to je taky v RAM a bohuzel se pocita jako 'shmem', takze to vubec neni zrejme, ze je to vlastne tim...
"Problem" prameni z toho, ze pokud neexistuje /var/log/journal, uklada systemd logy do tmpfs pod /run/log/journal - a na to se da docela rychle narazit.
Resenim je vyrobit adresar /var/log/journal a otocit tu VPSku, bude po problemu.
Proc jsme si toho do ted nevsimli s OpenVZ, zjistuju, ale vypada to, ze uz mame hlavniho vinika, proc nam "nevysvetlitelne" ubyva RAMka s pribyvajicim uptime na tech OpenVZ strojich...
V novych sablonach uz to Aither opravil:
https://github.com/vpsfreecz/vpsadminos-image-build-scripts/commit/2872ff1b5...
Ve stavajicich VPS to doresime skriptem behem nasledujicich par desitek hodin.
Ale ty VPSky, kterych se to tyka, zacnou logovat na spravne misto az od restartu (chystame v nasledujicich dnech update vsech vpsadminos nodes na Linux 5.9, takze explicitni restart, pokud s tim zrovna nebojujete, asi potreba neni).
/snajpa
On 2020-10-19 15:18, Petr Gregor wrote:
Zdar, rád bych poprosil o pomoc s debugováním OOM killů v mém VM. Měl jsem za to, že mám spoustu volného místa a proto mě kill překvapil (díky za nové reportování z vpsadminu!). VM monitoruji zabbixem a ten tvrdí, že dostupné paměti je dost (špička na konci je kill)
výstup z free -m vypadá takto:
root@hostingf:~# free -m total used free shared buff/cache available Mem: 1000 238 100 621 661 761 Swap: 0 0 0
/proc/meminfo MemoryAvailable sedí se zabbixem a free: "MemAvailable: 777548 kB"
Trošku zarážející je, že "volné" paměti je pouze 100M. Rozhodující pro OOM je ale "dostupná" paměť, že?
V příloze posílám výstup z dmesg náležící k OOM killu.
Není mi jasné, proč OOM kill vůbec nastal. Součet všech rss v dmesg reportu ani zdaleka nedosahuje 1G. Předpokládám, že mi nějak uniká něco podstatného, ale nevím moc co hledat. Budu rád za každé nakopnutí.
Gregy
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list

Ahoj,
ďakujem za tipy, funguje.
Ešte dodám, že pôvodný `/run/log/journal` mal permissions `rwxr-sr-x`, tak som okrem `mkdir -p /var/log/journal` spravil ešte `chmod 2755 /var/log/journal` a potom `systemctl daemon-reload`
Využitie pamäte reportované vo vpsAdmine kleslo o cca. 400 MB.
Tomáš
On 19.10.2020 15:56, Matěj Koudelka wrote:
IMHO neni třeba otáčet vps, stačí systemctl daemon-reload
Matěj Koudelka
+420 604 266 933
On Mon, 19 Oct 2020 at 15:39, Pavel Snajdr snajpa@snajpa.net wrote:
Ahoj,
podle toho reportu jsi mel cca 600 MB v tmpfs, to je taky v RAM a bohuzel se pocita jako 'shmem', takze to vubec neni zrejme, ze je to
vlastne tim...
"Problem" prameni z toho, ze pokud neexistuje /var/log/journal, uklada systemd logy do tmpfs pod /run/log/journal - a na to se da docela rychle narazit.
Resenim je vyrobit adresar /var/log/journal a otocit tu VPSku, bude po problemu.
Proc jsme si toho do ted nevsimli s OpenVZ, zjistuju, ale vypada to, ze uz mame hlavniho vinika, proc nam "nevysvetlitelne" ubyva RAMka s pribyvajicim uptime na tech OpenVZ strojich...
V novych sablonach uz to Aither opravil:
https://github.com/vpsfreecz/vpsadminos-image-build-scripts/commit/2872ff1b5...
Ve stavajicich VPS to doresime skriptem behem nasledujicich par desitek hodin.
Ale ty VPSky, kterych se to tyka, zacnou logovat na spravne misto az od restartu (chystame v nasledujicich dnech update vsech vpsadminos nodes na Linux 5.9, takze explicitni restart, pokud s tim zrovna nebojujete, asi potreba neni).
/snajpa
On 2020-10-19 15:18, Petr Gregor wrote:
Zdar, rád bych poprosil o pomoc s debugováním OOM killů v mém VM.
Měl
jsem za to, že mám spoustu volného místa a proto mě kill překvapil (díky za nové reportování z vpsadminu!). VM
monitoruji
zabbixem a ten tvrdí, že dostupné paměti je dost (špička na konci je kill)
výstup z free -m vypadá takto:
root@hostingf:~# free -m total used free shared
buff/cache
available Mem: 1000 238 100 621
661
761 Swap: 0 0 0
/proc/meminfo MemoryAvailable sedí se zabbixem a free:
"MemAvailable:
777548 kB"
Trošku zarážející je, že "volné" paměti je pouze 100M. Rozhodující pro OOM je ale "dostupná" paměť, že?
V příloze posílám výstup z dmesg náležící k OOM killu.
Není mi jasné, proč OOM kill vůbec nastal. Součet všech rss
v
dmesg reportu ani zdaleka nedosahuje 1G. Předpokládám, že mi nějak uniká něco podstatného, ale nevím moc co hledat. Budu
rád
za každé nakopnutí.
Gregy
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list
Community-list mailing list Community-list@lists.vpsfree.cz http://lists.vpsfree.cz/listinfo/community-list
community-list@lists.vpsfree.cz
-
 Matěj Koudelka
Matěj Koudelka -
 Pavel Snajdr
Pavel Snajdr -
 Petr Gregor
Petr Gregor -
 vudiq@vudiq.sk
vudiq@vudiq.sk